파이썬의 BeautifulSoup 라이브러리를 이용해서 웹 페이지를 스크랩하는 간단한 예제 코드입니다.
예제를 위한 사이트는 뽐뿌 게시판으로 정했습니다.

우선 전체 코드를 먼저 올리고 간단한 설명은 뒤에 있습니다.
전체 코드
# 뽐뿌/뽐뿌 게시판 스크랩
# 타겟 주소: https://www.ppomppu.co.kr/zboard/zboard.php?id=ppomppu
import pandas as pd
from urllib.request import urlopen
from requests import get
from bs4 import BeautifulSoup
import os
g_sTargetUrl = 'https://www.ppomppu.co.kr/zboard/zboard.php?id=ppomppu'
g_sResultFile = 'result.xlsx'
def ParsetURL(sURL) :
itemList = []
urlPrefix = 'https://www.ppomppu.co.kr/zboard/'
# 10 페이지 연속 조회
html = get(sURL)
# 한글이 깨지면 아래처럼 euc-kr 명시해 준다.
bsObj = BeautifulSoup(html.content.decode('euc-kr','replace'), "html.parser")
# tr 중에 calss가 list0 또는 list1 속성을 가진 행을 찾는다.
data1 = bsObj.findAll('tr', {'class': ['list0', 'list1']})
for v in data1:
item = []
a_Tag = None
sLink = ''
for td in v.find_all("td"):
sTd = td.get_text()
sTd = sTd.replace('\n', '')
sTd = sTd.replace('\t', '')
sTd = sTd.replace('\xa0', '')
sTd.strip()
item.append(sTd)
a_Tag = td.find('a')
if (a_Tag == None):
continue
if a_Tag['href'].find('view.php?') == 0 :
sLink = urlPrefix + a_Tag['href']
item.append(sLink)
print(item)
itemList.append(item)
return itemList
def exportExcel(itemList, fileName):
writer = pd.ExcelWriter(fileName, engine='xlsxwriter')
colHeader=['번호', '분류', '글쓴이', '제목', '등록일', '추천', '조회', 'URL']
df = pd.DataFrame(columns=colHeader)
for data in itemList:
item = {}
print(data[0])
item['번호'] = data[0]
item['분류'] = data[1]
item['글쓴이'] = data[2]
item['제목'] = data[3]
item['등록일'] = data[6]
item['추천'] = data[7]
item['조회'] = int(data[8])
item['URL'] = data[9]
df.loc[len(df)] = item
print(item)
###########################################
# 조회 역순으로 정렬
df = df.sort_values(by='조회', ascending=False)
# Convert the dataframe to an XlsxWriter Excel object.
df.to_excel(writer, sheet_name='folders')
# Close the Pandas Excel writer and output tdf = df.sort_values(by='통합순위')he Excel file.
writer.save()
os.startfile(fileName)
return
# testSite1()
itemList = []
itemList = ParsetURL(g_sTargetUrl)
exportExcel(itemList, 'd:\\dnld\\' + g_sResultFile)
코드 설명
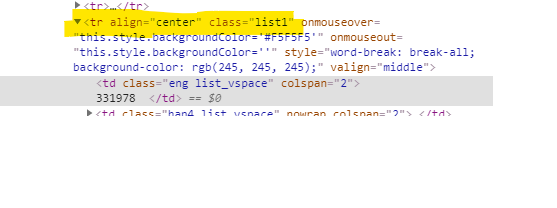
뽐뿌 게시판의 table을 확인해 보면 하나의 행 <tr> 들은 클래스가 list1 임을 알 수 있습니다.
html = get(sURL)
# 한글이 깨지면 아래처럼 euc-kr 명시해 준다.
bsObj = BeautifulSoup(html.content.decode('euc-kr','replace'), "html.parser")
# tr 중에 calss가 list0 또는 list1 속성을 가진 행을 찾는다.
data1 = bsObj.findAll('tr', {'class': ['list0', 'list1']})
위 코드는 BeautifulSoup을 이용해 해당 url을 열고 html을 파싱 해서 원하는 태그와 태그의 속성을 가져옵니다. 코드에서는 tr 중에 class 속성이 list0 또는 list1 인 tr을 모두 찾아 data1에 넣습니다.
특히 html 파싱 할 때 한글이 깨지는 경우에는 위 코드를 참고 해서 추가하면 됩니다.
for v in data1:
item = []
a_Tag = None
sLink = ''
for td in v.find_all("td"):
sTd = td.get_text()
sTd = sTd.replace('\n', '')
sTd = sTd.replace('\t', '')
sTd = sTd.replace('\xa0', '')
sTd.strip()
item.append(sTd)
a_Tag = td.find('a')
if (a_Tag == None):
continue
if a_Tag['href'].find('view.php?') == 0 :
sLink = urlPrefix + a_Tag['href']
item.append(sLink)
print(item)
itemList.append(item)그런 다음 data1에 있는 tr 들을 하나씩 꺼내서 다시 열 단위(td)로 분리하고 이를 item 에도 추가하는 식입니다. 특히 td 내에 링크 속성(a)이 있으면 url을 구해서 같이 배열에 넣게 됩니다.
def exportExcel(itemList, fileName):
writer = pd.ExcelWriter(fileName, engine='xlsxwriter')
colHeader=['번호', '분류', '글쓴이', '제목', '등록일', '추천', '조회', 'URL']
df = pd.DataFrame(columns=colHeader)
for data in itemList:
item = {}
print(data[0])
item['번호'] = data[0]
item['분류'] = data[1]
item['글쓴이'] = data[2]
item['제목'] = data[3]
item['등록일'] = data[6]
item['추천'] = data[7]
item['조회'] = int(data[8])
item['URL'] = data[9]
df.loc[len(df)] = item
print(item)
###########################################
# 조회 역순으로 정렬
df = df.sort_values(by='조회', ascending=False)
# Convert the dataframe to an XlsxWriter Excel object.
df.to_excel(writer, sheet_name='folders')
# Close the Pandas Excel writer and output tdf = df.sort_values(by='통합순위')he Excel file.
writer.save()
os.startfile(fileName)
return위 함수는 모여진 item 들을 pandas를 이용해서 저장한 다음 '조회' 역순으로 정렬시키고 엑셀 파일로 저장하게 됩니다

많은 정보가 이미 인터넷에 수없이 많이 있어서 BeautifulSoup의 많은 기능들을 조금만 잘 활용해도 할 수 있는 일이 많겠네요
'개발 > 파이썬' 카테고리의 다른 글
| [파이썬] 여러 리스트를 하나로 합쳐주는 zip 함수 (0) | 2020.02.16 |
|---|---|
| 파이썬 아나콘다 32비트 설치/재설치 (4) | 2019.11.14 |
| [파이썬] 딕셔너리를 이용한 카운팅, 정렬 예제 (2) | 2019.11.02 |
| [파이썬] 함수 호출 CALL BY VALUE/CALL BY REFERENCE (2) | 2019.10.06 |
| 파이썬의 for 루프 (1) | 2019.06.16 |
| [CREON PLUS API 활용] BlockRequest 와 Request (362) | 2018.12.11 |

댓글