MFC 로 거의 10년이 넘게 유지 보수해 오던 회사 프로젝트를 드디어(이제야?) 유니코드로 이전한다고 합니다. 막상 유니코드로 이전하려고 하니, 그 동안 익숙하게 사용해 오던 함수들, 특히 strcpy, memcpy 와 같은 표준 C 라이브러리가 애물단지가 되고 말았습니다. 진작에 갔어야 하는데, 차일피일 미루다 보니 한번에 수정하기엔 너무 부담스러울 정도로 덩치가 커져 버렸네요.
유니코드를 위해 엄청난 소스 수정을 앞두고(저희 회사 프로그램 소스가 제가 생각해도 엄청(?)납니다)스스로 하나씩 배워가고 있는 내용(아주 초보적인 내용이긴 합니다만)을 조금 정리했습니다.
유니코드 에 대해서
유니코드를 알려면 현재 저희가 너무나 친숙하게 사용하고 있는 ASCII 코드를 알 필요가 있습니다. ASCII 코드는 한 바이트의 코드로 모든 영문자를 저장할 수 있는 아주 간단한 코드 테이블입니다. PC 가 주로 영문 권에서 만들어지다 보니 ASCII 는 당연히 표준처럼 쓰였고, 한 바이트로는 표현할 수 있는 글자 수가 너무 많은 우리나라와 같은 많은 나라들은 각기 ASCII 코드를 확장해서 2바이트로 표현하기 시작했습니다.
글자 한자를 표현하기 위해 너무나 복잡한 코드 체계가 존재했기 때문에 이러한 혼동을 잠재우기 위해 지구상의 모든 글자를 담을 수 있는 코드 테이블을 만든 게 유니코드입니다.
이러한 유니코드를 실제 바이트에 표현하기 위해 여러 가지 인코딩 방식이 등장했습니다.
그 중에 가장 널리 쓰이는 방식으로 하나의 글자 표현에 2바이트를 사용하는 UCS-2(2바이트 사용) 또는 UTF-16(16비트사용) 과, 영어 문자는 한 바이트만 사용하고 그 외 나라 글자들은 2바이트~최대 6바이트까지 할당하는 UTF-8 등이 있습니다.
유니코드 관련 “조엘 온 소프트웨어: 유쾌한 오프라인 블로그” 4장 “개발자가 꼭 알아둬야 할 유니코드와 문자 집합에 대한 고찰” 부분을 읽어 보시길 권해 드립니다 (이전에 읽었던 부분인데 이번에 유니코드 조사 하면서 다시 읽으니 느낌이 틀리더군요. 쉬우면서도 통쾌한 글쓰기에 한해서는 조엘을 따라올 사람이 없어 보입니다.)
유니코드 데이터 타입
1. 유니코드 - Wide Character 로 16비트 코드를 가집니다. 윈도우 NT 운영체제에서는 이러한 2바이트 짜리 유니코드를 내부적으로 사용하고 있습니다. 2바이트로 고정된 문자길이는 MBCS와 달리 프로그램으로 다루기 쉽게 되어 있습니다. (한 글자는 무조건 2바이트이니까) C/C++ 에서는 wchar_t 배열로 표현되고, 포인터는 wchar_t* 로 표현할 수 있습니다.
2. MBCS/DBCS – MBCS(Multi-Byte Character Set)은 하나의 문자가 한 바이트 이상으로 구성된 문자열 셋을 말합니다. 이제 거의 사용되지 않는 윈도우 9x 계열의 운영체제는 MBCS로 글자를 표현하고 있습니다. DBCS 는 MBCS 의 한 유형으로, 특정 문자는 한 바이트, 다른 문자는 여러 바이트를 사용해서 글자를 표현하고 있습니다. (주로 한국, 일본, 중국 등과 같이) C/C+ 에서는 MBCS/DBCS 를 unsigned char 배열로 표현하고, 포인터는 unsigned char* 로 표현합니다. 문자가 한 바이트 또는 두 바이트로 이뤄지다 보니 한 글자 단위로 옮겨 다니기 위해 머리 아프게 계산해야 할 수 있는데 이를 위해 ChartNext, ChartPrev 같은 함수가 제공됩니다.
Visual C++ 에서는 MBCS 는 DBCS 를 의미하고, 한 글자는 한 바이트 또는 두 바이트로만 이뤄질 수 있습니다. (두 바이트 초과되는 글자는 지원하지 않습니다)
3. ANSI – 8비트만으로 모든 영문 문자열과, 서유럽 문자열을 표시할 수 있습니다. 마이크로소프트 윈도우 ANSI 문자 셋은 ANSI 표준에 근거하여 ISO 8859/x 와 일부 문자열을 추가된 형태입니다. ANSI 는 SBCS 로 불리고 C/C++ 에서는 ANSI 문자열을 char 배열, char* 로 표현할 수 있습니다.
4. TCHAR/_TCHAR – 오늘의 주인공입니다. TCHAR 는 마이크로소프트에서 만든 문자열 TYPE 으로 컴파일 타임에 지정된 옵션에 따라 문자열을 유니코드, MBCS, ANSI 각각으로 매칭될 수 있도록 해 주는 타입입니다. TCHAR 를 사용함으로써 상황에 맞는 문자열처리를 할 수 있게 됩니다. 마이크로소프트에 특화된 C 런타임 라이브러리 헤더 파일인 tchar.h 는 일반 텍스트 타입을 _TCHAR 로 선언하고 있습니다. (ANSI C/C++ 컴파일러 호환성을 유지하기 위해 컴파일러가 별도로 타입 정의한 내용은 앞에 언더바(‘_’) 를 붙여 표시하도록 하고 있기 때문에 _TCHAR 라고 합니다) 만약 Pre-define 에 __STDC__ 를 선언하지 않으면(디폴트로 선언되어 있지 않습니다) ANSI 호환성을 사용하지 않겠다는 의미가 되고 다시 tchar.h 에는 _TCHAR 을 TCHAR 로 선언해서 사용할 수 있도록 하고 있습니다. 윈32 운영체제용 헤더 파일인 winnt.h 에도 TCHAR 가 선언되어 있는데 이 헤더 파일은 ANSI 컴파일러 호환성과 상관이 없기 때문에 _TCHAR 대신 TCHAR 로만 선언하고 있습니다.
Win32 API 에서 텍스트 다루기
문자열을 입력으로 요구하는 모든 Win32 API 에는 MBCS 버전(MBCS를 사용하지 않는 윈도우는 ANSI 버전으로 취급)과, 유니코드 버전 2가지를 모두 제공합니다.
실제로 윈도우의 타이틀을 변경하는 SetWindowText API 는 SetWindowText 라는 API 가 존재하는 것이 아니라 UNICODE 설정여부에 따라, SetWindowTextA(ANSI 버전) 와 SetWindowTextW API 가 실제 불려지게 됩니다.
#ifdef UNICODE
#define SetWindowText SetWindowTextW
#else
#define SetWindowText SetWindowTextA
#endif // !UNICODE
윈도우 NT 계열에서는 내부적으로 유니코드 문자열만 사용하기 때문에 SetWindowTextA 라고 호출하면, 내부적으로 문자열을 유니코드로 변경한 다음 다시 유니코드 버전인 SetWindowTextW 함수를 호출한다고 합니다. (API 호출 성능이라는 입장에서 보면 유니코드버전으로 개발하는 것이 성능적인 이점이 있습니다)
유니코드나 MBCS 용 모듈을 그때그때 필요에 따라 만들기 위해서는 char 나 wchar 와 같은 변경하기 힘든 문자열 타입이 아니라, 컴파일 시점에 자동으로 타입 전환이 가능한 TCHAR 를 이용하는 것이 중요합니다.
유니코드 프로젝트 세팅하기
유니코드로 프로젝트를 빌드하기 위해서는 UNICODE 와 _UNICODE를 전처리기에 등록해야 합니다. UNICODE 는 윈도우 API 처리 함수에서 사용하는 전처리기이고, _ UNICODE 는 C 런타임 라이브러리에서 판단하는 라이브러리입니다. Visual Studio 2003 이상 버전(2005, 2008 포함) 에서는 프로젝트 속성에서 간단하게 사용할 문자 집합을 지정할 수 있습니다.
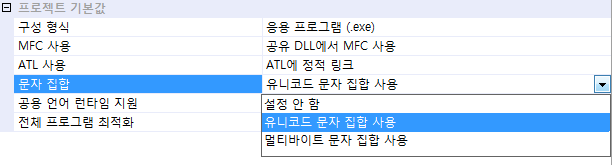
유니코드 텍스트 파일
일반적으로 메모장(notepad) 에서 텍스트를 작성하고 저장하면 ANSI 포맷으로 저장됩니다. 유니코드로 파일을 저장하려면 새 이름으로 저장하기를 눌러 인코딩 방식을 선택할 수 있습니다.
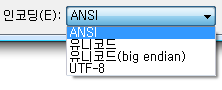
유니코드로 저장된 파일을 읽어 보면 재미있는 사실을 발견하게 됩니다.
Hello
라고 5자로 저장한 텍스트 파일을 바이너리 에디터로 열어 보면 아래와 같이 저장되어 있음을 알 수 있습니다.
ff fe 48 00 65 00 6c 00 6c 00 6f 00
여기에서 FF FE 는 이 텍스트 파일이 유니코드로 저장되어 있음을 얘기하고, 나머지 텍스트들은 UCS-2 즉 2바이트 유니코드로 저장되어 있습니다.
유니코드임을 나타내는 문자는 원래 FE FF 인데, Big Endian 에서는 원래대로 FE FF 로 기록되고, IBM-PC 계열인 윈도우에서는 Little Endian 방식이라 FF FE로 바이트 위치가 역전되어 저장됩니다.
CStdioFile 과 같은 MFC 파일 클래스는 유니코드에서 어떻게 작동할까요?
MFC 에서 텍스트 파일 저장 및 불러오기에 자주 사용하는 CStdioFile 클래스의 WriteString 으로 기록한 파일은 유니코드형식일까요? 아니면 ANSI 버전일까요? 처음 생각은 유니코드 버전에서 이 함수를 호출하면 당연히 유니코드로 저장된다고 생각했습니다.
CStdioFile file;
file.Open(_T("c:\\work\\abc.txt"), CFile::modeWrite | CFile::modeCreate | CFile::typeText);
file.WriteString(_T("Hello"));
하지만, 유니코드 버전에서 저장을 해도 파일 형식은 여전히 ANSI 버전이었습니다.
마찬가지로 위에서 만든 텍스트 파일을 ReadString 을 통해 읽어오면 ANSI 텍스트 파일이 자동으로 wchar_t 로 문자열로 다시 저장되는 것을 확인할 수 있었습니다.
file.Open(_T("c:\\work\\abc.txt"), CFile::modeRead | CFile::typeText);
TCHAR tRead[100];
file.ReadString(tRead, sizeof(tRead) / sizeof(TCHAR));
file.Close();
마지막으로 abc.txt 파일을 메모장을 이용하여 유니코드 포맷으로 변경한 후 다시 CStdioFile:: ReadString 으로 호출하면 어떻게 되는지도 테스트 해 봤습니다. 결과는 역시 깨집니다. 결국 CStdioFile 에서는 ANSI 텍스트만 다뤄야 하는 것으로 보입니다.
관련해서 구글링을 해 보니 다음처럼 유니코드 파일을 지원하는 버전을 별도로 개발한 사람도 있네요
A UTF-16 Class for Reading and Writing Unicode Files
CStdioFile-derived class for multibyte and Unicode reading and writing
이와 유사하게 WritePrivateProfileString 함수로 저장한 ini 파일도 기대를 저버리지 않고(?) ANSI 버전으로 저장됩니다.
유니코드용 문자열 클래스
MFC 의 CString 은 베이스타입을 char 나 wchar 가 아닌 TCHAR 를 사용한 템플릿 클래스로 선언되어 있기 때문에 유니코드 선언 여부에 따라 자동으로 해당 버전의 문자 클래스로 만들어 집니다. CString 을 많이 사용한다면 일단 선언하는 변수명부터 수정해야 하는 부담은 없습니다.
반면에 STL 의 string 은 자동으로 TCHAR 를 선택할 수 있도록 되어 있지 않습니다. 따라서 유니코드용 버전에서는 string 대신 wstring 을 선언해야 합니다. 이렇게 사용할 경우, TCHAR 를 사용함으로써 컴파일 옵션에 따라 처리할 문자열 타입을 쉽게 전환할 수 없기 때문에 아래처럼 기존 string/wstring 선언 뒤에 tstring 선언을 추가하는 방식으로 정의해서 사용하는 방법이 있겠네요
typedef basic_string<char, char_traits<char>, allocator<char> >
string;
typedef basic_string<wchar_t, char_traits<wchar_t>,
allocator<wchar_t> > wstring;
typedef basic_string<TCHAR, char_traits< TCHAR >,
allocator< TCHAR > > tstring;
유니코드 문자열 처리하기
유니코드의 문자를 처리하기 위해서는 wcs* 로 시작하는 wchar_t 를 다루는 함수를 사용해야 합니다. 이 역시 TCHAR 형을 다루는 함수가 미리 준비되어 있는데, wcs* 부분을 _tcs* 로 변경해 주면 됩니다. 아래는 문자열을 다루는 C 런타임 함수들과 그에 상응하는 TCHAR 형 함수들입니다. ANSI UNICODE TCHAR strlen() wcslen() _tcslen() strcat() wcscat() _tcscat() strchr() wcschr() _tcschr() strcmp() wcscmp() _tcscmp() strcpy() wcscpy() _tcscpy() strstr() wcsstr() _tcsstr() strrev() _wcsrev() _tcsrev() printf() wprintf() _tprintf() sprintf() swprintf() _stprintf() scanf() wscanf() _tscanf()
유니코드 문자열 처리 시 주의 사항
유니코드 문자열을 다룰 때 가장 혼동되는 부분 중에 하나는 배열의 개수와, 실제 배열의 크기를 다루는 부분입니다. 예를 들어 아래와 같은 코드를 실행하면
TCHAR szTemp[10] = _T("Hello");
int nLen = _tcslen(szTemp);
ASSERT(nLen == 5);
유니코드 환경이든, ANSI 환경에서든 _tcslen() 의 리턴값은 반드시 5여야 합니다.
유니코드 함수 API 도움말에 들어 있는 size_t 타입이 의미하는 것이 배열내 요소의 개수인지, 배열이 차지하는 메모리 공간의 크기인지 항상 확인하고 프로그램을 작성해야 합니다.
또한 memcpy 와 같은 함수는 당연히 실제로 복사할 바이트 수를 지정해야 합니다.
TCHAR szTemp2[10];
memcpy(szTemp2, szTemp, sizeof(szTemp));
sizeof(szTemp) 는 유니코드 하에서는 20바이트, MBCS 환경에서는 10이 됩니다.
아래 코드는 memcpy() 를 사용해서 szTemp2 의 문자열 끝에 szTemp 문자열을 붙이는 작업을 합니다. MBCS 환경에서는 sizeof(char) 가 1 이었기 때문에 문자열을 다룰 때 sizeof(char) 를 빼먹은 경우가 많고 이 때문에 MBCS 를 유니코드로 변경할 때 알고도 당하는 실수를 여러 번 경험합니다.
TCHAR szTemp[10] = _T("Hello");
TCHAR szTemp2[10] = _T("Hey");
memcpy(szTemp2 + _tcslen(szTemp2), szTemp, _tcslen(szTemp) * sizeof(TCHAR));
// MBCS 환경에서라면
// memcpy(szTemp2 + strlen(szTemp2), szTemp, strlen(szTemp));
윈도우 API 를 다룰 때도 주의가 필요합니다.
RegSetValueEx 함수를 호출할 때 맨 마지막 인자는 szValue 의 버퍼크기를 담아 보내야 하기 때문에 아래와 같이 sizeof(TCHAR) 를 계산해야 제대로 인자가 전달됩니다.
TCHAR szKeyName[30];
TCHAR szValue[30];
RegSetValueEx(hKey, szKeyName, 0, REG_SZ, (LPBYTE)szValue, _tcslen(szValue) * sizeof(TCHAR) + 1);
GetModuleFileName() 에서는 마지막 인자로 문자열의 배열 개수를 필요로 하기 때문에 아래와 같이 사용해야 합니다. (알고 나면 간단하지만 각 API 별로 의미를 충분히 파악해서 사용하지 않는다면 순식간에 프로그램이 죽을 수 있으니 조심해서 코딩해야 합니다.)
TCHAR szModuleName[MAX_PATH];
DWORD dwStrLen= GetModuleFileName(NULL, szModuleName, MAX_PATH);
유니코드 문자열 변환 함수
MBCS 에서 유니코드로 전환하려면 mbstowcs 와 MultiByteToWideChar 2가지 함수를 사용할 수 있습니다.
size_t mbstowcs(
wchar_t *wcstr,
const char *mbstr,
size_t count
);
UINT CodePage,
DWORD dwFlags,
LPCSTR lpMultiByteStr,
int cbMultiByte,
LPWSTR lpWideCharStr,
int cchWideChar
);
반대로 유니코드를 MBCS 형태로 변경하려면 wcstombs 또는 WideCharToMultiByte 함수를 사용하면 됩니다.
char *mbstr,
const wchar_t *wcstr,
size_t count
);
UINT CodePage,
DWORD dwFlags,
LPCWSTR lpWideCharStr,
int cchWideChar,
LPSTR lpMultiByteStr,
int cbMultiByte,
LPCSTR lpDefaultChar,
LPBOOL lpUsedDefaultChar
);
위 함수가 조금 복잡하게 느껴지면 ATL 에서 제공하는 정말 간단한 매크로를 사용해서 컨버전하는 것도 괜찮은 방법입니다. (ATL 로 COM 을 다룰 때는 A2W, W2A 를 애용했던 1人 이었습니다 ^^)
// 컨버젼이전에항상임시변수를선언해야합니다
USES_CONVERSION;
TCHAR wTemp[10] = _T("Hello");
char sTemp[10];
strcpy(sTemp, W2A(wTemp));
ASSERT(strcmp(sTemp, "Hello") == 0);
[참고 서적]

ATL INTERNALS (by Brent Rector, Chris Sells) - 2장 ATL Smart Types

조엘 온 소프트웨어: 유쾌한 오프라인 블로그 - 4장 “개발자가 꼭 알아둬야 할 유니코드와 문자 집합에 대한 고찰”
'개발' 카테고리의 다른 글
| Source Line Counter (2) | 2008.03.19 |
|---|---|
| Visual Studio 2005의 Code Analysis 기능 (3) | 2008.03.11 |
| 마이너가 된 IE 8, 그리고 생각해 봐야 할 하위호환성 문제 (4) | 2008.03.07 |
| 윈도우 비스타 어플리케이션 아이콘 (0) | 2008.02.29 |
| Visual Studio 버전 별 STL 지원 (17) | 2008.02.28 |
| 윈도우 배경화면을 자동으로 변경하는 프로그램 – ezWallPaper 0.1 (58) | 2008.02.21 |
댓글